When a Ruby on Rails application grows over the years it either rots in to a big ball of mud or it gets dissected in to services–the first is universally recognized as a bad approach while service oriented architecture has a good reputation and gets used as a way to handle code complexity.
That’s like tidying a messy drawer by moving items in to separate rooms before neatly arranging what’s in the drawer.
When good object oriented practices aren’t enough to understand what the whole Ruby on Rails application does I tackle code complexity with component based architecture to deliver business value with an incremental modular design–if and when the time comes I can use the components as a stepping stone to a service oriented architecture. To appreciate the next part of the article you should be familiar with component based architecture or have read a component based Rails architecture primer.
I will present a simplified example adapted from a real life application where users can see entities on a webpage, the entities are upserted and in some case deleted by two 3rd party providers causing a search index update, the entities are also available to 3rd party consumers.
First I will describe the workflow using a service oriented architecture and then using component based Rails architecture.
Service oriented workflow
The application is split in 5 projects: publisher, persister, API, UI, SharedModels.
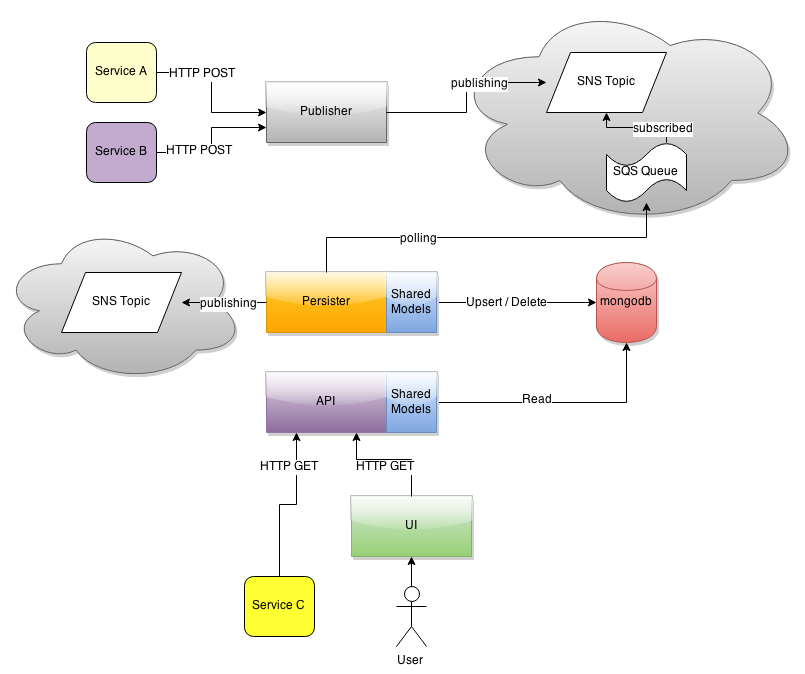
SharedModels is a library published on a private gem server and a dependency of the persister and API projects to access the database.
Two external services (A and B) hit the publisher service with an HTTP POST to change or add entities, publisher then publishes a message on an Amazon Web Services SNS topic and an AWS SQS queue is subscribed to it. The persister scheduled job pulls an entity from that queue and upserts or deletes it from a database using the SharedModels, then it publishes a message to an AWS SNS topic to update a search index.
The end user visits a website trough the UI application that makes HTTP GETs to the API application that reads entities from the database via the SharedModels gem.
The API application has an external service (C) reading entities.
Considerations
If no other service needs the raw data from Service A and Service B publisher seems redundant–decoupling it from persister is premature optimization and a violation of YAGNI. If the load from Service A and B is very high the persistence can be moved to a background job to speed up the request response cycle. Having those two services communicating via AWS means local end-to-end tests need dedicated AWS SNS Topics and SQS queues requiring an extra steps in development.
Separating publisher from api conceals the fact that they are the application interface to the outside world–the first is a write API the second a read API.
Having the ui project fetching entities via HTTP calls to the api rather then a direct database access must be well motivated–testing the api isn’t a good reason, enforcing data encapsulation to expose a subset of the full domain model could be.
Having a published library SharedModel that two projects depend on generates overhead during development even if you use GIT precommit hooks to facilitate local Ruby GEMs development. In some circumstance this is a necessary evolution of your application as I mention in handling component based Rails applications change.
Let’s assume this service oriented architecture is over-engineered for the application load and look at how component based architecture delivers a modular design that can evolve to services.
Component based architecture
A component based application lives in a single repository but if it has several portions–admin, public, API–they can be deployed independently.
In a component based application the SharedModels library becomes a domain_logic local component speeding up development by skipping the publishing process. The api and public_ui components will depend on it.
The publisher project and API project become the api component. Service A and B hit it and within the request response cycle an entry is upserted or deleted from the database using the domain_logic. After an entry is persisted the search reindex is triggered via the site_search component that dispatch messages to AWS SNS.
The UI project is now a public_ui component that access the database directly depending on the domain_logic component avoiding unnecessary HTTP calls to the API.
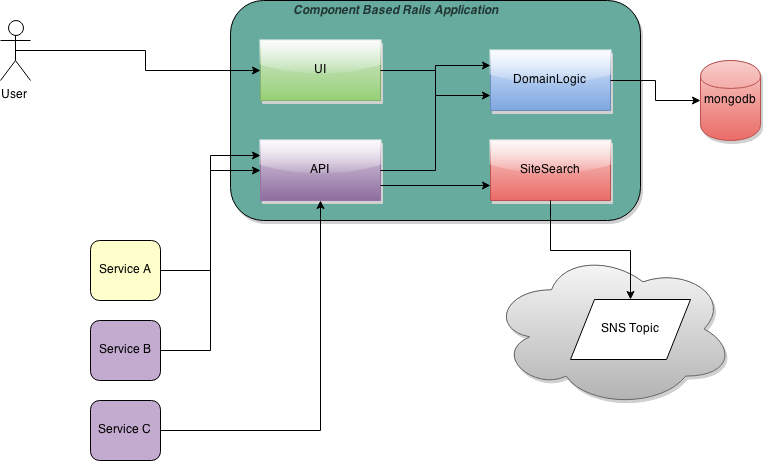
Here’s how the local components directory would look:
/components
/api
/public_ui
/domain_logic
/site_searchEvolving components
If the API load is significantly higher then the two portions api and public_ui can be deployed to separate infrastructures using the technique explained in Feature flagging portions of your Ruby on Rails application with engines.
If the write API is under heavy load its computation could be delegated to a simple queuing system like Sidekiq or more complex messaging solutions–at this point splitting the application in multiple repositories might be required and some components might need to become shared via a private gem server.
The service architecture might be what this application needs at some point in the future but capacity planning and business requirements should drive that not guessing or bravado.
Blindly committing to that architecture upfront is a mistake because developers will have to cope with the downsides of an application split in several moving parts with no benefit.