Having a suite of automated tests can be a blessing and a curse. When consistently working it can ensure no regression is introduced while developing new features. When it has inconsistently failing tests (often referred to as flaky tests) it generates mistrust in the entire automated test approach.
I came up with a workflow to help identify and monitor inconsistently failing automated tests to increase trust in your build and your process.
Do not commit broken code
Might sound naive but you can facilitate that by making sure your build is:
easy to run
create a ./build script to run the build locally before committing, ie. in a Ruby project you can combine rspec and jasmine like this:
#!/bin/bash
exit_code=0
bundle install | grep Installing
bundle exec rspec spec
exit_code+=$?
bundle exec rake app:jasmine:ci
exit_code+=$?
exit $exit_codedocumented
ensure new developers are onboarded on the testing workflow by pair programming while following (and if necessary updating) a wiki page documenting the process and possible gotchas for future reference.
fast
the suite should not run for more then 10 minutes. A longer time would create pockets of unproductive time inbetween delivering features, developers might entirely give up running tests.
If your build takes longer focus on parallelizing your tests or pruning excessive integration tests.
Ensure the build is green on CI
Once the build is green on your workstation ensure it’s green in a shared environment accessible by the team: your continuous integration (CI) server.
If the build fails on CI do not dismiss it as a flaky test yet. If you run the build again and fails you’re likely to have a CI only failing test.
Surely there are reasons why it worked on your workstation and not on CI. Examining the stack trace and the circumstances might reveal what went wrong.
Examples of consistently failing on CI only are:
- full stack (PhantomJS/Selenium) tests using different default viewports between CI and workstation
- CI timezone different from workstation
- mismatching libraries/binaries versions between workstation and CI
- concurrent builds sharing database
Do not leave a consistently failing test on CI or people will loose trust in the automated build
It’s usually good to keep your peers updated with your efforts but in some environments you might want to skip that. I’ve seen people dismissing these errors as “it’s only failing on CI so it’s not worth spending time on it” and they’d rather leave the build failing or skip the test.
In my opinion that is a mistake that brings to mind the broken window theory:
Consider a building with a few broken windows. If the windows are not repaired, the tendency is for vandals to break a few more windows. Eventually, they may even break into the building, and if it’s unoccupied, perhaps become squatters or light fires inside. Wikipedia
Identify a flaky test
If simply running again a broken build suddenly fixes a previously failing test you got a “flaky test”. But do not dismiss it just yet, take a few moments to examine the fail stack trace and the circumstances to get a glimpse of what went wrong.
An example of this might be two CI builds pointing to the same database and creating inconsistent states on each other tests.
The solution might not always be quick or easy, so after you’ve spent the allocated time document the flaky test to help the next team member that will likely have to face it.
Document the flaky test
Rather then asking your colleagues if they know the CI error you’re seeing search it in your archives. I like to create github issues marked flaky-test
If the failing test is already in your archives add a comment with the build number it was spotted on

If you can’t find one create a new issue, file one failing test per github issue:
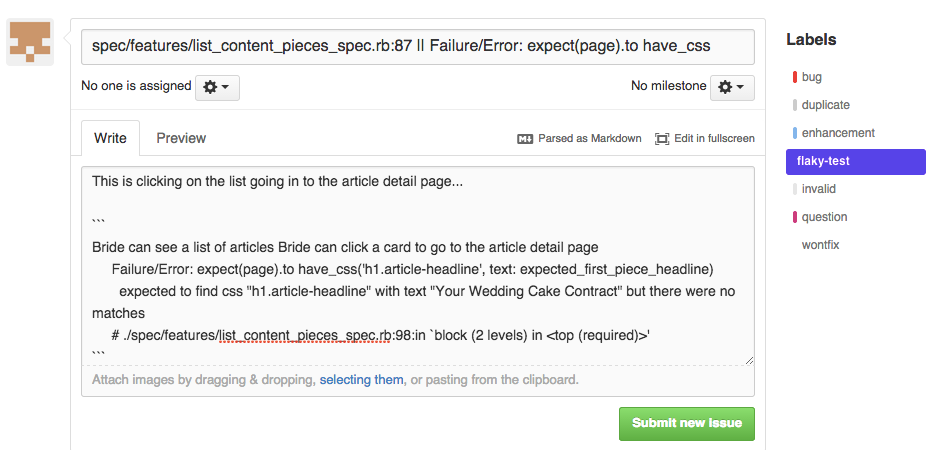
I like the title to be: ERRORING_FILE_NAME_AND_LINE || APPLICATION EXCEPTION for example: spec/features/preview/article_mobile_spec.rb:24 || Capybara::Poltergeist::TimeoutError and mark the issue with the tag flaky-test.
We now have the information to focus resolution efforts on frequently occurring issues, perhaps pinpoint some fails to a 3rd party system having issues at that time
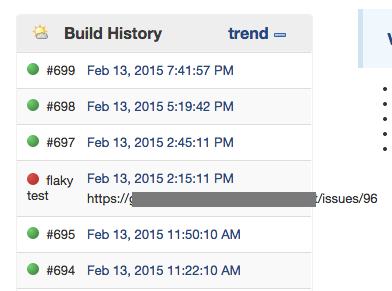
After confirming a flaky test add that information in jenkins with the “edit build information”. A title “flaky test” and description the github issue that tracks the flaky test.
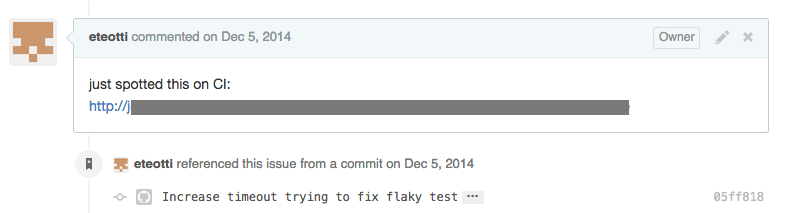
If you commit a possible fix, referencing the flaky-test issue in the commit message will add an entry to the comments informing your teammates of what attempt or progress has been made:
Throttle your network connection to external sites
Flaky test can be caused by external resources misbehaving. I worked on an Angular application using a payment gateway iframe that would always be present and work well during development and on production but trigger intermittent test failures. Using Charles proxy I was able to intercept and slow down connections to the payment gateway making the flaky test fail consistently. In this particular case it wasn’t worth spending time to fix a problem that we didn’t see in production but adding a comment explaining the root cause helps increase the team confidence in the build.
Develop in a virtual machine
Running your development in a virtual machine matching the CI server (and your deploy server) libraries configuration helps revealing errors during TDD rather then waiting until the CI server runs the build.
Using a vagrant virtual box I’ve seen user interfaces relying heavily on AJAX calls failing way more frequently or even consistently. An example:
While starting typing a new article a JS heavy UI contacts the backend to persist it in a new document. If your feature doesn’t notify the UI about success or fail of that data persistence, your test will continue assuming that call was successful perhaps hitting the publish button for a document that will not be found and cause a “flaky test” fail. The next time the first AJAX call might finish before the second and the test will pass.
I’ve seen this error formerly a CI flaky test transforming in a consistent fail when run in a vagrant virtual box. This is an example of a poorly built feature unveiled by an integration test.
Conclusion
In my experience inconsistent automated test fail for a reason and dismissing them is an unsustainable policy.
It’s important to maintain trust in the automated test build. Knowing that there is a process in place for identifying and tracking flaky tests will help establish or solidify that trust.
I hope these steps will help shape your CI build from a black box showing green or red lights in to a more controlled process.
You can download the workflow barebone Github Gist.